

Abstract
Correct and timely detection of plasma confinement regimes and edge localized modes (ELMs) is important for improving the operation of tokamaks. Existing machine learning approaches detect these regimes as a form of post-processing of experimental data. Moreover, they are typically trained on a large dataset of tens of labeled discharges, which may be costly to build. We investigate the ability of current machine learning approaches to detect the confinement regime and ELMs with the smallest possible delay after the latest measurement. We also demonstrate that including unlabeled data into the training process can improve the results in a situation where only a limited set of reliable labels is available. All training and validation is performed on data from the COMPASS tokamak. The InceptionTime architecture trained using a semi-supervised approach was found to be the most accurate method based on the set of tested variants. It is able to achieve good overall accuracy of the regime classification at the time instant of 100 µs delayed behind the latest data record. We also evaluate the capability of the model to correctly predict class transitions. While ELM occurrence can be detected with a tolerance smaller than 50 µs, detection of the confinement regime transition is more demanding and it was successful with 2 ms tolerance. Sensitivity studies to different values of model parameters are provided. We believe that the achieved accuracy is acceptable in practice and the method could be used in real-time operation.
Export citation and abstract BibTeX RIS
1. Introduction
During a fusion experiment in a tokamak, the plasma can transit between two basic confinement regimes; the standard low-confinement regime (L-mode) and a regime with improved confinement (H-mode). Each experiment begins with the plasma being in the L-mode and it may eventually transit to H-mode when satisfactory conditions–mainly sufficient heating power–are reached [2]. Due to reduced particle and energy losses and consequent increases in energy and particle confinement times, the H-mode is nowadays considered a reference scenario for high-performance discharges. Unfortunately, an MHD instability called ELM is ubiquitous to the H-mode. ELMs cause high and abrupt energy and particle losses that lower the overall confinement and can, in the worst case, damage the plasma-facing components. This all motivates the need to create a good automatic detector of plasma confinement regimes and ELMs that could improve our capabilities to study and control these features.
Recent work has shown that it is possible to use machine learning to build a classificator of plasma confinement regimes [3]. However, up to now, the greatest attention was paid mostly to distinguishing the L-mode from the H-mode [3–5]. The current most advanced approaches are based on a long-short-term-memory network (LSTM) with convolutional feature extraction [6, 7], with the former publication focused only on the L-H transitions and the latter considering also ELMs, but only as a secondary output that does not directly influence L/H classification metrics. These models work under the assumption that information about L-H transitions is hidden not only in short-term trend changes but also in long-term correlations. Although both approaches are relatively accurate, they cannot be used effectively in real-time scenarios. Another weak point of the approach is the need for a lot of labeled data to properly learn parameters in the LSTM layers.
In this work, we aim to get closer to the real-time classification of plasma states inside the tokamak with a limited number of labeled data points. Moreover, we classify plasma states that are not interchangeable with confinement regimes. Instead of just L-mode and H-mode, we are detecting L-mode (L), inter-ELM, or ELM-free part of H-mode (H), leading edge of ELMs (ELM ) and trailing edge of ELMs (ELM
) and trailing edge of ELMs (ELM ). The reason for dividing ELMs into two separate states is their different nature and importance. The leading edge represents the actual event when the edge plasma tears off and hits the chamber wall. On the other hand, the trailing edge is only an intermediate state during the recovery of the pedestal that smoothly transits into the H-mode state. Illustration of the distinction to L-H transition and detail of the ELM classification is displayed in figure 1.
). The reason for dividing ELMs into two separate states is their different nature and importance. The leading edge represents the actual event when the edge plasma tears off and hits the chamber wall. On the other hand, the trailing edge is only an intermediate state during the recovery of the pedestal that smoothly transits into the H-mode state. Illustration of the distinction to L-H transition and detail of the ELM classification is displayed in figure 1.

Figure 1. Comparison of common confinement regimes and plasma states used in this work. COMPASS discharge #16962.
Download figure:
Standard image High-resolution imageOur key distinctions from previous works are the following:
- With the limited amount of labeled data, we investigate the possibility to extract information from unlabeled data using techniques of semi-supervised learning (SSL).
- We investigate the use of different architectures that process the data and perform a sensitivity study of their performance. We show the advantages of other architectures over the convolutional-LSTM used in previous works.
- Aiming at real-time application, we investigate the capability of the model to predict the plasma state with as low a delay as possible.
- We provide several evaluation metrics that may be useful in different application contexts such as when the system needs to detect and react to the change of the plasma state.
2. Data description
2.1. Source of the data
Data used in this paper were extracted from the database of the COMPASS tokamak that was operated by the Institute of Plasma Physics under the Czech Academy of Sciences between 2006–2021 [8]. COMPASS was a mid-size (R0 = 0.56 m, a = 0.2 m) tokamak with a toroidal magnetic field in the range BT
= 0.8–2.1 T, plasma current up to 400 kA, auxiliary heating by NBI  1.5 MW, capable of achieving both Ohmic and NBI-assisted H-modes.
1.5 MW, capable of achieving both Ohmic and NBI-assisted H-modes.
2.2. Measured diagnostic signals
The automatic data collection system of the COMPASS records tens of diagnostic signals for each discharge. However, not all of them are available for all discharges and only a few are known to contain information relevant to the plasma mode classification. Based on expert knowledge of the operators of the COMPASS tokamak, we have selected the five signals as the input features at a given time step: Dα
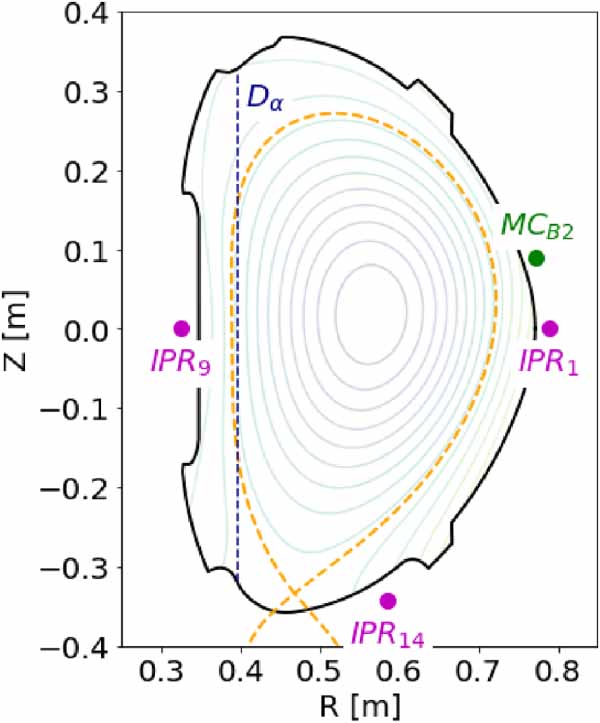
, IPR14, IPR1, IPR9 and MC , summarized in table 1. The location of sensors measuring these data is displayed in figure 2, detailed description of each feature follows.
, summarized in table 1. The location of sensors measuring these data is displayed in figure 2, detailed description of each feature follows.

Figure 2. Illustration of location of sensors measuring the selected signal on a poloidal cross-section of the COMPASS tokamak.
Download figure:
Standard image High-resolution imageTable 1. List of the signals from the COMPASS tokamak used in detection of the plasma mode.
| Abbr. | Description | Sensor |
|---|---|---|
| Dα | Radiation of deuterium | Photomultiplier |
| IPR1 | Outer magnetic field | Internal partial Rogowski coil no. 1 |
| IPR9 | Inner magnetic field | Internal partial Rogowski coil no. 9 |
| IPR14 | Lower part of magnetic field | Internal partial Rogowski coil no. 14 |
MC
| Outer magnetic field (toridally shifted) | Mirnov coil B theta 02 |
The Dα signal represents measurement of radiation of the Balmer-alpha line of deuterium (656.1 nm) along vertical chord as illustrated in figure 2 [8]. The amplitude of Dα is strongly correlated with the rate of particle loss from the plasma column. Therefore it is ideal for recognition of plasma states (figure 1) [6].
Internal partial Rogowski (IPR) coils measure the poloidal component of the magnetic field at different poloidal positions around the plasma. In total, the COMPASS tokamak is equipped with more than a hundred magnetic coils surrounding the vessel. From all those signals, we selected only three that are used by the operators for manual mode detection. The sensors are selected to surround the lower part of the plasma, see figure 2. Specifically, IPR14 measures the magnetic field at the lower part of the vessel, while IPR1 and IPR9 focus on the outer and inner side, respectively. The IPR14 signal was selected specifically because it is sensitive to the presence of the geodesic acoustic mode, whose presence/absence can be a strong indicator of the plasma regimes [9]. The last signal, Mirnov Coil B theta 02 (MC ), measures a poloidal magnetic field, similarly to IPR, but its toroidal location is shifted from IPR1 by 155 degrees.
), measures a poloidal magnetic field, similarly to IPR, but its toroidal location is shifted from IPR1 by 155 degrees.
2.3. Labels
The dataset created for the numerical experiments consists of labeled (L/H/ELM /ELM
/ELM ) and unlabeled discharges. The database of COMPASS contains about 20 000 discharges, but only a few of them have a presence of the H-mode and ELMs fully labeled and revised by researchers.
) and unlabeled discharges. The database of COMPASS contains about 20 000 discharges, but only a few of them have a presence of the H-mode and ELMs fully labeled and revised by researchers.
Therefore, 31 most complete and consistently labeled discharges were chosen for the labeled dataset ( ) and another 20 unlabeled discharges were randomly selected to form an unlabeled dataset (
) and another 20 unlabeled discharges were randomly selected to form an unlabeled dataset ( ). The discharges contain a mix of Ohmic and NBI-assisted discharges and ELMing as well as ELM-free H-modes. The total duration of the plasma covered by the dataset is 7303 ms, out of which 4361 ms is labeled as L-mode, 1928 ms as H-mode, 217 ms as ELM-leading edge, and 797 ms ELM-trailing edge (1164 ELM events in total).
). The discharges contain a mix of Ohmic and NBI-assisted discharges and ELMing as well as ELM-free H-modes. The total duration of the plasma covered by the dataset is 7303 ms, out of which 4361 ms is labeled as L-mode, 1928 ms as H-mode, 217 ms as ELM-leading edge, and 797 ms ELM-trailing edge (1164 ELM events in total).
2.4. Preprocessing
In this section, we describe the preprocessing steps that are applied to the raw measured data, independently of the model that is used for prediction. All operations that are specific to the network architecture will be described later in the corresponding sections.
All used signals are recorded with a sampling frequency of 2 MHz. However, the information contained at frequencies above 200 kHz is redundant, so the signals have been downsampled in time by a factor of 10, corresponding to a sampling time 5 µs.
The next step of the preprocessing is scaling. Scaling is needed mainly due to different signals scales and because it allows models to train more effectively. All available data (labeled and unlabeled) were scaled together using the RobustScaler [10]:

which uses the median  and interquartile range (
and interquartile range ( ) instead of the common mean and standard deviation. That makes the scaling robust against outliers and abnormally big ELMs that are present in the data.
) instead of the common mean and standard deviation. That makes the scaling robust against outliers and abnormally big ELMs that are present in the data.
To exploit the potential of model architectures for sequence modeling (like RNN, CNN, etc), we need to construct overlapping sequences with an assigned label from the individual signals recorded in each time step. However, this requires the decision on the optimal length of the sequences. We have performed a simple feature selection procedure to explore the relevance of the time delayed values of the signals using various classical methods (ANOVA, Mutual information, etc). None of the selected feature sets contained values delayed more than 800 µs. Hence, the downsampled discharges were sliced into fixed-length sequences of length 800 µs. Each sequence contains 160 elements (data vectors from 160 time steps) and the sequences are generated with a stride of 10 (50 µs), i.e. two successive sequences share 150 elements.
Since labels are available for each time step, we need to choose which label to assign for each sequence. We choose to associate each sequence with the label of a sample that appears p µs before the end of the sequence. The p is called label delay and treated as a parameter, see figure 3. For real-time application the lower delay the better:


Figure 3. Illustration of multiple label delays (p) for specific sequence #16962. The figure shows the values of the Dα signal in a sequence (800 µs long). The colors represent what kind of label is associated with each time step. The label for the whole sequence may differ based on the chosen delay parameter p.
Download figure:
Standard image High-resolution imageProcessing of all the included discharges results in a dataset consisting of 128 000 labeled (Nl ) and 97 400 unlabeled (Nu ) sequences, i.e.:

where  and
and  is the one-hot encoded class label.
is the one-hot encoded class label.
In order to properly test the performance of the models, we divided the discharges with labels into 20 discharges used for training and 11 discharges used for testing. These discharges were split into sequences and the sequences from the training discharges were divided randomly into the training set (80% of the sequences) and validation set (20% of the sequences). All sequences from the testing discharges form the testing set.
3. Methods
3.1. Neural networks types
Neural networks (NN) are widely used across various domains, such as image classification, object detection, or natural language processing. However, each domain prefers different types of networks as well as architectures. Recurrent and convolutional neural networks (RNNs and CRNNs) are part of most of the state-of-the-art (SOTA) approaches dealing with sequence modeling.
3.1.1. Recurrent neural networks.
Recurrent neural networks (RNNs) are a type of NNs that were invented for sequence modeling [11]. Traditional NNs assume all inputs and outputs to be independent of each other, which is not true in the case of sequences. For that reason, RNNs introduce the concept of a hidden state , that incorporates information from previous time steps. A prominent example of RNN is the long short-term memory (LSTM) network [12] which is capable of detecting long-term dependencies in data. This architecture introduces a cell state in addition to the existing hidden state, which serves as long-term memory. The single LSTM layer consists of four dense layers interconnected so that information can be effectively memorized or forgotten.
3.1.2. Convolutional neural networks.
Convolutional neural networks (ConvNets) are alternatives to standard feed-forward NNs and are designed to work with grid structured data, i.e. images and sequences. ConvNets are able to successfully capture the spatial and temporal dependencies in the data through the application of relevant filters that are learned directly from data. Using these filters is more feasible because their weights are shared within a single layer, which reduces the number of parameters and speeds up training.
InceptionTime [13] (IT) is a ConvNet specially designed for time series classification. InceptionTime is similar to a residual network (ResNet), but each residual block is comprised of three inception modules instead of simple convolutional layers. The Inception module, as a basic building block of InceptionTime, consists of five independent convolutional layers (in which two are bottlenecks) with different receptive fields (see [13] for details). This mimics the LSTM's feature, which allows IT to capture diverse dependencies, short-term as well as long-term.
3.1.3. Convolutional recurrent networks.
Convolutional recurrent networks (CRNN) are a combination of CRNN and RNNs that should take advantage of both approaches. Convolution layers are typically used for feature extraction from the raw data and then processed with recurrent layers. This type of network was already previously used for plasma classification [6].
The distinction between the above-mentioned architectures is primarily in the way how they process subsequent records in the sequence, as illustrated graphically in figure 4. The RNN assumes a transition model between every time step of the sequence (horizontal arrows between green dots). The convolutional network processes a chunk of the sequence by a convolution filter (denoted by colored triangles). The CRNNs combine those two principles, by modeling a transition model between the results of the convolution filters.

Figure 4. Illustration of the tools used by the tested architectures for processing of the sequence. Blue horizontal arrows represent the flow of hidden state between green recurrent cells. Colored triangular areas symbolize the receptive field of convolutions.
Download figure:
Standard image High-resolution image3.1.4. Other architectures.
New architectures frequently appear with the rapid pace of development of the deep learning field. One of the prominent approaches is the transformer-type architecture using self-attention layers [14]. This architecture is known for its high memory and computational cost (scaling with  in the number of contexts N), especially during inference. For this reason, we did not consider it in our experiments. However, recent efforts in reducing the computational cost [15] make this approach a promising direction for future research.
in the number of contexts N), especially during inference. For this reason, we did not consider it in our experiments. However, recent efforts in reducing the computational cost [15] make this approach a promising direction for future research.
3.2. Semi-supervised learning
Semi-supervised learning (SSL) is a set of machine learning techniques that use a small amount of labeled data combined with a large number of unlabeled data in order to train or strengthen typically data-demanding models. SSL can also reduce overfitting and help models generalize. One of the methods that allow the exploitation of these attributes is the semi-supervised variational autoencoder (VAE) [16].
3.2.1. Variational autoencoder.
The VAE [17] is a generative model capable of discovering probabilistic distribution  , which generates data
, which generates data  . The key assumption of the model is that the data
x
is generated by some underlying process, represented by a latent variable
z
. In principle, the model approximates
. The key assumption of the model is that the data
x
is generated by some underlying process, represented by a latent variable
z
. In principle, the model approximates  , which is analytically intractable, by introducing the probability distribution of the generating process,
, which is analytically intractable, by introducing the probability distribution of the generating process,  . θ denotes parameters of the distribution. Those are connected through the relation:
. θ denotes parameters of the distribution. Those are connected through the relation:

where  is the prior distribution of the latent variable. To enable end-to-end training of the model, the generating distribution is accompanied by an encoding distribution
is the prior distribution of the latent variable. To enable end-to-end training of the model, the generating distribution is accompanied by an encoding distribution  . That produces such samples
z
that are most likely to lead to the generation of samples
x
with a high probability under
. That produces such samples
z
that are most likely to lead to the generation of samples
x
with a high probability under  , see figure 5.
, see figure 5.

Figure 5. Illustration of the variational autoencoder. The encoder network (yellow) yields the mean and variance of the latent variables. The decoder (green) network generates reconstruction of the original sample.
Download figure:
Standard image High-resolution imageThe encoding and generating distribution are usually modeled by Gaussian distributions, with mean and variance being an output of NNs, called the encoder and decoder, respectively. These are optimized simultaneously, using variational inference, in order to maximize (variational) lower bound on the log-likelihood  , with:
, with:

where the first term on the right-hand side is the expected log-likelihood (negative reconstruction error) and the second term is the KL-divergence between the prior and posterior distributions of
z
, that regularizes parameters of encoder and forcing  and
and  to be close to each other.
to be close to each other.
3.2.2. Semi-supervised VAE.
Standard VAE can be freely extended to a more advanced form, such as the conditional VAE [16], where data are being generated not only by continuous latent variable
z
but also by discrete latent variable
y
, that are usually known. The semi-supervised VAE (SSVAE) [18] is special version of conditional VAE, where discrete variables
y
, e.g. labels, are known only for a fraction of the dataset and thus the encoder needs to approximate a joint posterior distribution  instead of previous
instead of previous  . This extension well matches the need of the studied application.
. This extension well matches the need of the studied application.
Assume that z is conditioned by x and y and that the variable y depends only on x , then both distributions can be modeled by separate encoders:

where the approximate posterior distribution of z and y is assumed to be Multivariate Normal and Categorical, respectively,


Vector functions  ,
,  and
and  are then represented by NNs. Illustration of such model is shown in figure 6.
are then represented by NNs. Illustration of such model is shown in figure 6.

Figure 6. Illustration of the semi-supervised variational autoencoder, the encoder (yellow) and decoder (green) networks of the VAE are complemented by the classifier (red).
Download figure:
Standard image High-resolution imageThe variational lower bound for this model is then given as the sum of the lower bound for labeled data  and the lower bound for unlabeled data
and the lower bound for unlabeled data  . However, in the case of SSVAE, which is meant to improve performance of classifiers, the final objective function is yet extended by expected log-likelihood of the classifier:
. However, in the case of SSVAE, which is meant to improve performance of classifiers, the final objective function is yet extended by expected log-likelihood of the classifier:

where α is scaling parameter and  is empirical distribution over labeled data
is empirical distribution over labeled data  , and internal loss functions are:
, and internal loss functions are:


The expectations are evaluated using the reparametrization trick [17] and trained using the ADAM optimizer. (Relation of supervised and semi-supervised learning).
Remark Note that the classifier of the supervised approach is also part of the SSVAE under notation  . The VAE in SSVAE can be interpreted as a regularization of the supervised training.
. The VAE in SSVAE can be interpreted as a regularization of the supervised training.
4. Results
The application of the methods to plasma mode identification may be analyzed from multiple viewpoints. We refrain from analyzing details of machine learning setup and focus on potential implications of the approach to practical application. We first summarize the experimental setup and then provide answers to questions: which neural architecture to use, how the quality of prediction depends on the time delay of the prediction, and how accurately is the transition of the mode localized in time. Recall, that collection of the data and their pre-processing has been described in section 2. Our implementation is available at https://github.com/aicenter/Plasma-state-identification-paper.
4.1. Experimental setup
All types of NNs have multiple hyperparameters. Since the choice of suitable hyperparameters/architectures is essential for good performance of models, we follow the standard protocol of dividing the data into training/validating/testing sets where the hyperparameters are selected on the validation data. Hyperparameters of all models and evaluation metrics are now described in detail.
4.1.1. Models and their hyperparameters.
Hyperparameters of simple CRNN and RNN are rather generic, such as the depth of the network, the number of filters or hidden neurons, filter sizes, and activation functions, see
In essence, InceptionTime is also a convolutional NN. However, the architecture is rather specific and its performance is so different from ordinary CNN that we decided to exclude it from CNNs and distinguish it as a separate type. Its hyperparameters reflect the architectural choices. More detailed description of this model is in section 3.1.2.
Since CRNN is a combination of CNN and RNN, the number of its hyperparameters is the union of hyperparameters for each architecture. The search for the best combination would be computationally expensive since the training of RNN alone is computationally costly. To avoid excessive architecture tuning, we decided to use an already proved CRNN architecture from [6], which happens to be the SOTA in the plasma confinement regime classification. However, we still perform the search for the best auxiliary parameters such as learning rate, batch size, etc.
4.1.2. Evaluation metrics.
Interpretation of the results is strongly dependent on the chosen metric. Since any metric reflects only some aspect of the model performance, we report three metrics—precision, recall and F1 score and comment on their similarities and differences.
These metrics were chosen due to imbalanced number of samples for each considered class, which is: L-mode: 55%, H-mode: 31%, ELM : 3% and ELM
: 3% and ELM : 11%. Under such conditions, the common metric of accuracy would be misleading [19].
: 11%. Under such conditions, the common metric of accuracy would be misleading [19].
The precision and recall metric for each of the K classes are in our case defined using a confusion metrics (figure 7) as follows:

where precisioni
/recalli
is the precision/recall for class i. In experiments with more than two classes, the terms precision and recall will be used to denote for the average precision across the classes, i.e.  .
.

Figure 7. Confusion matrix.
Download figure:
Standard image High-resolution imageInterpretation of these metrics is intuitive. The precision is the proportion of positive identifications that are actually correct and the recall is the proportion of actual positives that were identified correctly. The choice of the relevant metrics depends on the purpose of the experiment. In general, we would like to have a method that achieves good performance in both of these metrics. The standard compromise metric is the F1 score, which is a harmonic mean of precision and recall:

Since the F1 score is suitable for imbalanced problems, we choose to report it as our primary metric. We also provide the remaining metric where they reveal additional information.
4.2. Performance of architectures
In the first experiment, we demonstrate that adding unlabeled data and using semi-supervised training helps to improve performance of the models. Every model type was trained twice: (a) in supervised manner, using only labeled data and (b) in semi-supervised manner, using all available data. The label delay for this experiment was set to  s.
s.
Performance of all tested model types is summarized in figure 8 via box plots of F1 score, calculated on a test dataset. The uncertainty in the box plots is over all hyperparameter settings such as the number of hidden neurons, layers, etc, listed in table A1 in the appendix. Note that all model types achieve higher average F1 scores when trained using the semi-supervised approach. The most significant improvement in performance can be observed for the InceptionTime, which also achieves consistently the highest performance of all architectures. Therefore, this model will be further analyzed in detail in the subsequent sections.

Figure 8. Comparison of supervised and semi-supervised training approaches for all tested model types. The box plots were computed over scores of all used hyperparameter samples. The results are for label delay equal  s.
s.
Download figure:
Standard image High-resolution imageThe worst-performing model type appears to be the CRNN. This result is unexpected because CRNN should combine the advantages of convolutions and recursion, yet both CNNs and RNNs alone perform better. We conjecture that the problem may be in the excessive number of parameters of the CRNN model (twice more parameters than the InceptionTime) in combination with a lack of labeled data. Moreover, the training is not limited by epochs but is stopped only when the validation loss starts to increase.
An example of the best model's classification is shown in figure 9 4 . The most serious mistakes made by this model can be seen in figure A4 (1015–1020 ms) and in figure A5 (1203–1220 ms). These misclassifications are caused by the dynamical shaping of plasma in time.

Figure 9. Discharge #7070 colored with respect to model prediction. Accuracy on this discharge is 0.932 and F1 score is 0.873.
Download figure:
Standard image High-resolution image4.3. Towards real-time
In the second experiment, we investigate how performance changes with lowering of the label delay, i.e. providing less information from the future.
The easiest scenario to model is, obviously, when the label is located in the middle of the window, with the delay equal to 400 µs, because the true plasma state for the whole sequence is decided by its middle element (CNN point of view). The amount of information between the past and the future is thus balanced. As the label delay decreases, so does the amount of information from the future, making the classification task more difficult. This experiment aims to answer the question of how much accuracy is lost when approaching the real-time scenario, i.e. where the 0 µs label delay equals a situation where the model estimates the actual time, which could be used, e.g. for feedback control of the tokamak.
We focused mainly on the previously best InceptionTime and RNN, both trained using the semi-supervised approach. In theory, the RNNs should be better suited for smaller label delays since the label prediction is based on the state predicted at the end of the sequence. However, the InceptionTime outperforms the RNN even in this task, as shown in figure 10. Note that the performance of the InceptionTime is almost equal for label delays between 100 and 400 µs. In real-time, i.e. 0 µs label delay, the F1 score is at 0.725.

Figure 10. Sensitivity of the F1 score of plasma state classification on the delay of the label with respect to the end of the recorded data sequence. Only the best-performing model types (RNN and InceptionTime) are displayed via mean value (full line) and one standard deviation (colored area) computed on the training dataset over all hyperparameter settings.
Download figure:
Standard image High-resolution imageThe accuracy of the plasma state prediction with 100 us delay is very promising. However, for real-time applications such as feedback control it is necessary to incorporate the inference time of the model, which is about 1 ms for the InceptionTime. Such a long inference time severely limits the application of the method, and further is necessary to reduce it.
4.4. Investigation of transitions
In our last experiment, we focus on exploring the behavior of the best model (SSVAE InceptionTime) in detecting transitions. There are two plasma state transitions, namely the L-H and the H-ELM transition, that are important in the operation of the tokamak. It is important to state that H or H-mode has a different meaning in the context of those two transitions. In the case of H-ELM
transition, that are important in the operation of the tokamak. It is important to state that H or H-mode has a different meaning in the context of those two transitions. In the case of H-ELM transition, the H is the same 'ELM-free' H-mode we used till now. However, H in the L-H transition means 'general' H-mode, which includes ELMs.
transition, the H is the same 'ELM-free' H-mode we used till now. However, H in the L-H transition means 'general' H-mode, which includes ELMs.
Real-time detection of the mode transition may be important for several tasks, e.g. triggering additional diagnostics for detailed study of the transition, study of plasma recovery after the ELM, or feedback control of plasma. Each of these tasks has different requirements for the accuracy of transition detection and for the time delay of the detection. Therefore, we will study the accuracy of the detection as a function of the best achievable time delay caused by the required data. Time delay caused by the data processing is not considered yet. However, we expect it to be much lower than the data-dependent time delay.
In previous experiments, we considered the point-wise classification problem, where incorrect classification of a sequence label did not directly affect the classification of the following one. However, detection of a transition (a change in labels) is based on at least two consecutive decisions, and each oscillation of labels can cause false detection. In order to make the detection of the transitions more robust, the predicted class probabilities are post-processed using a moving average with a short delay (smoothing delay), and transitions are considered to be detected only if the labels remain the same for a certain period of time (transition length) after they changed.
Correct evaluation of the temporal localization of the transition is challenging as well since, even in the labeling process, it was not always evident where exactly the transitions occurred. Thus, certain tolerance in the temporal location of the transition must be allowed. The tolerance for the L-H transition is higher because it is more gradual than the H-ELM transition, where a change happens quickly.
transition, where a change happens quickly.
In this task, the knowledge about how much we can trust the prediction of the model (precision) and how many transitions the model identified (recall) are equally important. Therefore, in this case, we focus more on individual precision and recall scores instead of the combined F1 score. However, we use their modified versions known as the transition precision and the transition recall [20]. These metrics are not computed point-wise but using an evaluation window. The evaluation window can be described by its size (window size), i.e. how many previous and following points we consider in the evaluation. We will distinguish between one-sided and two-sided window, where the one-sided left takes into account only the previous, and the one-sided right only the following points. The window size can determine the tolerance of transition detection. For example, the transition precision (with a two-sided evaluation window ( s, 20 µs) can be interpreted as the probability that the actual transition will occur within 20 µs from the predicted transition. Similarly, for the transition recall.
s, 20 µs) can be interpreted as the probability that the actual transition will occur within 20 µs from the predicted transition. Similarly, for the transition recall.
Note from figure 11 that the precision and recall metrics of the L-H transition detection have different sensitivity to the transition length parameter of the pre-processing procedure. Specifically, the precision increases and the recall decreases with the transition length. This is because short transitions are often false positives which are filtered out for longer transition lengths and thus improving precision. On the other hand, it may happen that even some correctly detected short transitions are filtered out for longer transition lengths and thus decreasing recall. The trade-off is thus found as a compromise between those metrics in terms of the F1 score, which is analyzed in figure 12(a). A good compromise appears to be at 150 µs for the majority of the window sizes since it is the shortest value with a high F1 score.

Figure 11. InceptionTime: surface plot of the (two-sided) transition metrics—precision (left) and recall (right)—for L-H transition with changing transition length and evaluation window size. The label delay is standard  s and the smoothing delay is 50 µs.
s and the smoothing delay is 50 µs.
Download figure:
Standard image High-resolution image
Figure 12. InceptionTime: dependencies of the transition metrics for L-H transition with respect to (a) increasing transition length for selected evaluation window sizes 500–2500 µs, and (b) increasing size of evaluation window with fixed transition length 150 µs. The smoothing delay of  s and the labeling delay of 400 µs are the same for both figures.
s and the labeling delay of 400 µs are the same for both figures.
Download figure:
Standard image High-resolution imageIn the case of the H-ELM transitions, only transitions of length
transitions, only transitions of length  s (with smoothing delay is 5 µs.) are taken into account because ELM
s (with smoothing delay is 5 µs.) are taken into account because ELM is significantly shorter than any H-mode. Unlike L-H transition detection, the H-ELM
is significantly shorter than any H-mode. Unlike L-H transition detection, the H-ELM is much more accurate and faster. Additionally, mistakes within 25 µs are mostly due to the uncertainty in labeling. We also note that the ground truth labels mark the H-ELM
is much more accurate and faster. Additionally, mistakes within 25 µs are mostly due to the uncertainty in labeling. We also note that the ground truth labels mark the H-ELM transition between 25 and 50 µs before the actual rise of the Dα
signal; thus, the majority of the ELMs are detected before the ELM appears on Dα
(see figure 1).
transition between 25 and 50 µs before the actual rise of the Dα
signal; thus, the majority of the ELMs are detected before the ELM appears on Dα
(see figure 1).
Note that both one-sided windows are used in the figure 13(a) (left-sided in dashed line and right-sided in full lines). This figure allows us to assess the temporal calibration of the classifier as follows. If the transition is always detected before the true transition, the metrics in the right-sided window approach one, but that of the left-sided window approach zero. The two-sided metrics are obtained by summation of both sides. Since the metrics in figure 13(a) are almost symmetric, the transition is detected before or after the true transition with almost equal probability. Higher precision at the right-sided window compared to that of the left-sided indicate that the model detects transitions slightly prior to the true H-ELM transitions.
transitions.

Figure 13. InceptionTime: dependence of the transition metrics for H-ELM transition on the size of the one-sided and two-sized windows, respectively. In (a) dashed lines denote metrics for the left-sided windows and full lines denote metrics for the right-sided windows. The label delay is standard
transition on the size of the one-sided and two-sized windows, respectively. In (a) dashed lines denote metrics for the left-sided windows and full lines denote metrics for the right-sided windows. The label delay is standard  s, transition length is
s, transition length is  s and smoothing delay is 5 µs.
s and smoothing delay is 5 µs.
Download figure:
Standard image High-resolution imageUnfortunately, the model is not able to detect all ELMs because, apart from a few obvious mistakes, some ELMs are similar to one specific type of L-mode, where plasma returns into L-mode for a small period of time and then returns back to H-mode.
5. Conclusion
We have tested the latest deep learning techniques for sequence learning on data commonly used to detect transition modes in a tokamak. The best results were achieved by the InceptionTime classifier in combination with SSL. This architecture has outperformed all previously published models on the data from the COMPASS tokamak. Apart from the standard classification performance, we have studied the influence of the labeling delay on the quality of the mode predictions. We have shown that the maximum performance can be obtained with only 100 µs delay, which is acceptable for real-time applications. Also, we have studied the quality of the temporal location of the mode transition. We have demonstrated how metrics depend on transition length that parameterizes L-H transition and that with transition length equal to 150 µs, the model has reasonable precision within 2 ms tolerance. In addition, the detection of the H-ELM has good precision and recall within 50 µs tolerance. Implementation of the networks in the control systems is left for future work. Investigation of recent architectures, such as transformers, is also a promising research direction.
has good precision and recall within 50 µs tolerance. Implementation of the networks in the control systems is left for future work. Investigation of recent architectures, such as transformers, is also a promising research direction.
Data availability statement
The data generated and/or analyzed during the current study are not publicly available for legal/ethical reasons but are available from the corresponding author on reasonable request.
Acknowledgments
This work was supported by MEYS project LM2018117, grant SGS21/165/OHK4/3T/14 and Czech Science Foundation Project No. GA19-15229S and GA22-32620S. The access to the computational infrastructure of the OP VVV funded project CZ.02.1.01/0.0/0.0/16_019/0000765 'Research Center for Informatics' is also gratefully acknowledged.
Appendix.: Implementation details and additional results
Appendix. Hyperparameters

Figure A1. SSVAE-InceptionTime: confusion matrix computed on whole testing set. Testing set consists of 61 749 sequences (11 discharges). Large confusion between ELM and H-mode is expected due to large uncertainty of this boundary in the labeled data.
and H-mode is expected due to large uncertainty of this boundary in the labeled data.
Download figure:
Standard image High-resolution image
Figure A2. Convergence of the best-performing model (table A2). Training was stopped after 105 epochs due to meeting the early stopping criterion. The visualized loss is given by formula (8). The lowest validation loss value reached is −687.03. The label delay is equal to 400 µs.
Download figure:
Standard image High-resolution image
Figure A3. Convergence of the best-performing semi-supervised CRNN. Training was stopped after 197 epochs due to meeting the early stopping criterion. The visualized loss is given by formula (8). The lowest validation loss value reached is −533.09. The label delay is equal to 400 µs.
Download figure:
Standard image High-resolution image
Figure A4. SSVAE-InceptionTime: discharge #6963 colored with respect to model prediction. Accuracy on this discharge is 0.918 and F1 score is 0.830. Red rectangles highlight the area with the most serious mistakes in the top subfigure as well as in predicted probabilities for L-mode/H-mode.
Download figure:
Standard image High-resolution image
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure A5. SSVAE-InceptionTime: discharge #9596 colored with respect to model prediction. Accuracy on this discharge is 0.919 and F1 score is 0.844. Red rectangles highlight the area with the most serious mistakes in the top subfigure as well as in predicted probabilities for L-mode/H-mode.
Download figure:
Standard image High-resolution image{kind=link}
Table A1. Listing of all the used/tested hyperparameters. Symbol  represents feed-forward (dense) layer, where numbers before and after the arrow correspond to numbers of input and output neurons, respectively. IM stands for inception module [13].
represents feed-forward (dense) layer, where numbers before and after the arrow correspond to numbers of input and output neurons, respectively. IM stands for inception module [13].
| Model | Parameter | Value set |
|---|---|---|
| Common | Activation | {relu, swish, leaky relu} |
| Batch size | {64, 128, 256} | |
| Early stopping | Validation classification loss | |
| Optimizer | ADAM | |
| Learning rate | {0.001, 0.0005, 0.0001} | |
| SSL common | Latent dimension—
| {15, 30} |
| Scaling parameter α |


| |
Encoder 
| Distribution | Multivariate normal |

| ||
| Network type | Feed-forward | |
| Structure | 5×160  128 128  128 128  128 128  ( ( , ,  ) ) | |
Decoder 
| Distribution | Matrix normal |

| ||
| Network type | Feed-forward | |
| Structure |

 128 128  128 128  128 128  (5×160, 5) (5×160, 5) | |
| InceptionTime | No. inception blocks | {1, 2} |
| No. bottleneck channels | {16, 32, 64} | |
| Filter sizes in IM | {[1, 5, 11, 23], [1, 3, 7, 15]} | |
| No. channels per IM | {16×4, 32×4, 64×4} | |
| CNN | No. channels/structure | { [64, 64, 64, 64], [128, 128, 128, 128], [256, 256, 256, 256] } |
| Filter sizes | [5, 3, 3, 3] | |
| Stride | [1, 1, 1, 1] | |
| Padding | [2, 1, 1, 1] | |
| Max pooling | [0, 2, 0, 2] | |
| After convolutions | {[Flatten  256 256  4], [GAP 4], [GAP 4] } 4] } | |
| RNN | No. LSTMs | {1, 2} |
| No. LSTMs neurons | {64, 128, 256 } | |
| After LSTMs | {128  4, 128 4, 128  128 128  4, 128 4, 128  128 128  128 128  4 } 4 } | |
| CRNN | Detailed info in [6] | |
| Activation | Relu | |
| No. channels/structure | [64, 128, 256, 256, 256, 256, 256, 256] | |
| Filter sizes | [3, 3, 3, 3, 3, 3, 3, 3] | |
| Padding | [1, 1, 1, 1, 1, 1, 1, 1] | |
| Max pooling | [0, 2, 0, 0, 2, 0, 0, 2] | |
| Dropout | [0, 0.5, 0, 0, 0.5, 0, 0, 0.5] | |
| After conv/before LSTM | Flatten  64 64  32 32 | |
| Recurrent | 2-layer LSTM with 32 neurons | |
| After recurrent | 32  32 + dropout(0.5) 32 + dropout(0.5)  4 4 |
Table A2. Hyperparameters of the best SSVAE-InceptionTime used in section 4.4.
| Optimizer | ADAM |
|---|---|
| Learning rate | 0.0005 |
Latent dimension—
| 15 |
| Batch size | 64 |
| No. inception blocks | 2 |
| No. bottleneck channels | 64 |
| Filter sizes in IM | (1, 5, 11, 23) |
| No. channels per IM | 32×4 |
| Activation | Swish |
Footnotes
- 4
Hyperparameters of the best semi-supervised InceptionTime, which was selected with respect to the validation dataset, are described in table A2. Additional results such as confusion matrix or convergence for this specific model are listed in appendix (figures A1 and A2). Convergence of CRNN model is shown in figure A3 for comparison.