
Draft Sequencing Crested Wheatgrass Chromosomes Identified Evolutionary Structural Changes and Genes and Facilitated the Development of SSR Markers

 , , ,
, , ,  , ,
, ,  and
and
Abstract
:1. Introduction
2. Results
2.1. Chromosome Sorting and the Creation of Partial Assemblies
2.2. Genic Sequences Identified in the Assemblies
2.3. Repetitive DNA Sequences Identified in the Assemblies
2.4. Development of SSR Markers
2.5. Experimental Verification of Newly Designed SSR Markers
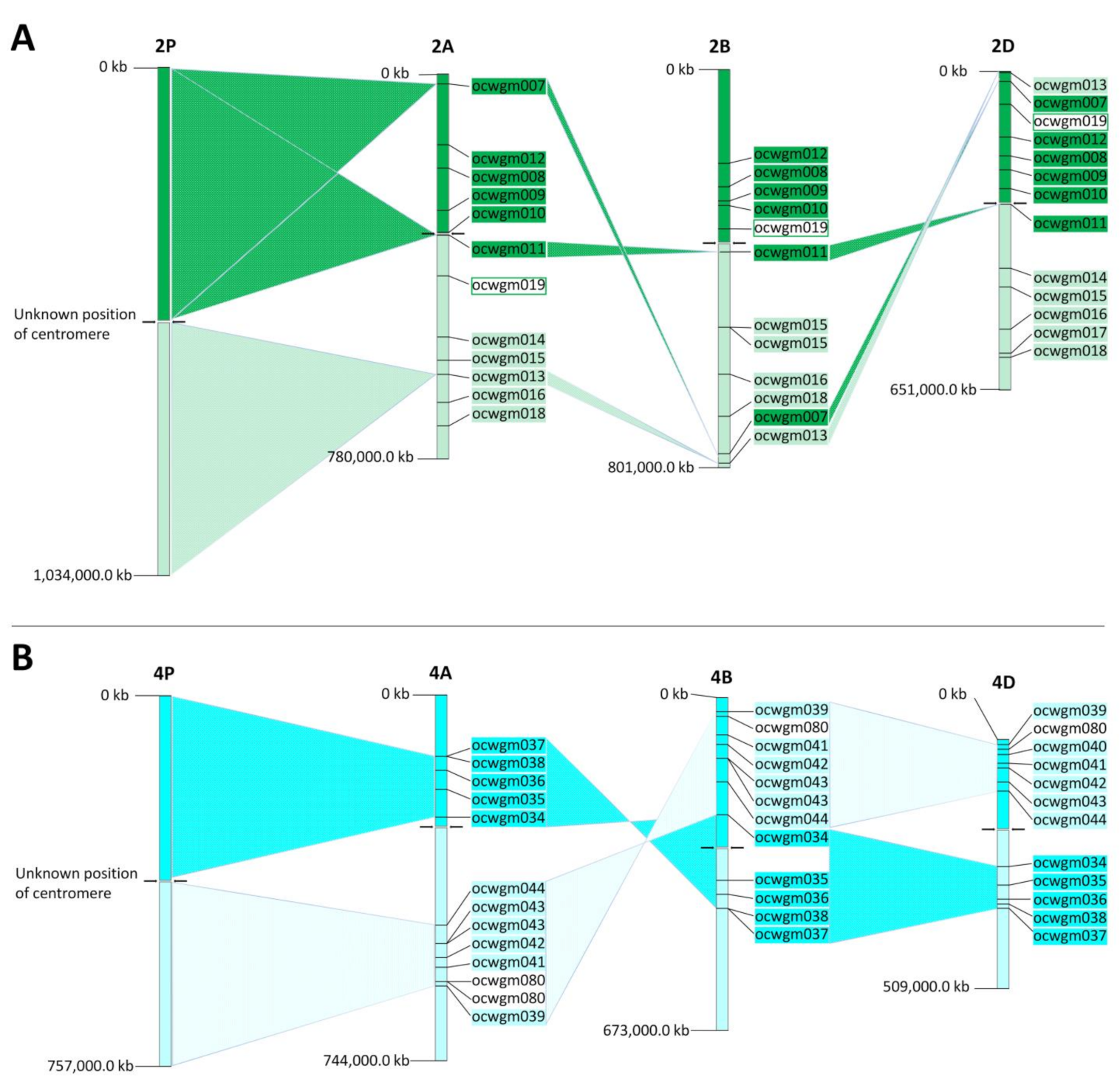
2.6. Orthologous Relationships between A. cristatum and Bread Wheat Chromosomes
3. Discussion
4. Materials and Methods
4.1. Plant Material and the Isolation of Genomic DNA
4.2. Chromosome Sorting and the Amplification of DNA
4.3. Illumina Sequencing
4.4. De Novo Assembly, Identification, and Verification of Chromosome-Specific SSR Markers
4.5. Annotation of Chromosome-Specific Sequences
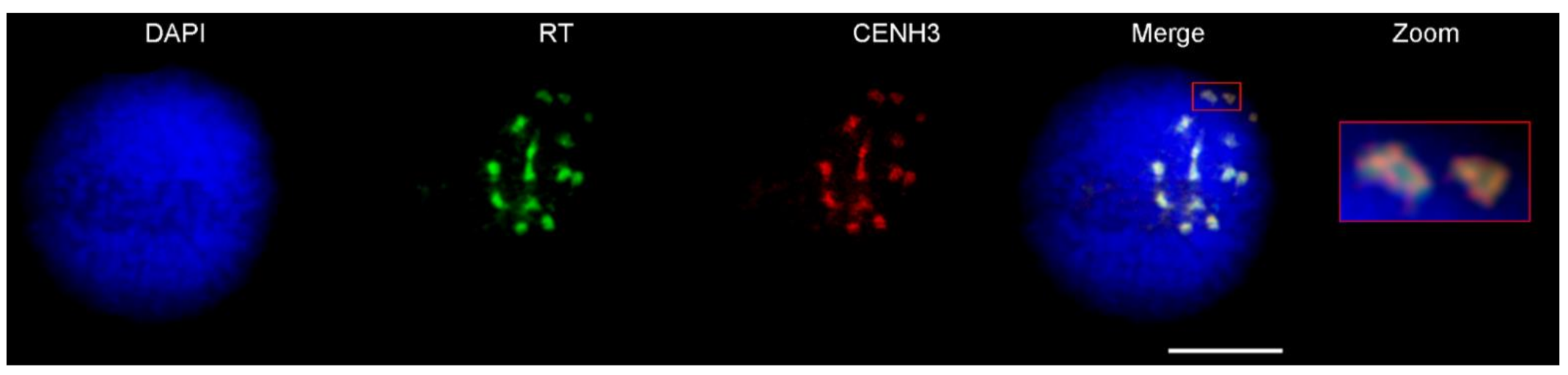
4.6. Immunostaining of Interphase Nuclei
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Asay, K.H.; Jensen, K.B. Wheatgrasses. Cool.-Seas. Forage Grasses 1996, 34, 691–724. [Google Scholar] [CrossRef]
- Asay, K.H.; Chatterton, N.J.; Jensen, K.B.; Jones, T.A.; Waldron, B.L.; Horton, W.H. Breeding Improved Grasses for Semiarid Rangelands. Arid. Land Res. Manag. 2003, 17, 469–478. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, W.; Han, H.; Song, L.; Bai, L.; Gao, Z.; Zhang, Y.; Yang, X.; Li, X.; Gao, A.; et al. De novo transcriptome sequencing of Agropyron cristatum to identify available gene resources for the enhancement of wheat. Genomics 2015, 106, 129–136. [Google Scholar] [CrossRef] [PubMed]
- Dewey, D.R. The Genomic System of Classification as a Guide to Intergeneric Hybridization with the Perennial Triticeae; Springer: Boston, MA, USA, 1984; pp. 209–279. [Google Scholar] [CrossRef]
- Limin, A.E.; Fowler, D.B. Cold hardiness of forage grasses grown on the Canadian prairies. Can. J. Plant Sci. 1987, 67, 1111–1115. [Google Scholar] [CrossRef]
- Asay, K.H.; Johnson, D.A. Genetic Variances for Forage Yield in Crested Wheatgrass at Six Levels of Irrigation. Crop Sci. 1990, 30, 79–82. [Google Scholar] [CrossRef]
- Dong, Y.S.; Zhou, R.H.; Xu, S.J.; Li, L.H.; Cauderon, Y.; Wang, R.R.-C. Desirable characteristics in perennial Triticeae collected in China for wheat improvement. Hereditas 1992, 116, 175–178. [Google Scholar] [CrossRef]
- Copete, A.; Moreno, R.; Cabrera, A. Characterization of a world collection of Agropyron cristatum accessions. Genet. Resour. Crop Evol. 2018, 65, 1455–1469. [Google Scholar] [CrossRef]
- Li, H.; Lv, M.; Song, L.; Zhang, J.; Gao, A.; Li, L.; Liu, W. Production and identification of wheat–Agropyron cristatum 2P translocation lines. PLoS ONE 2016, 11, e0145928. [Google Scholar] [CrossRef] [Green Version]
- Guo, Q.; Meng, L.; Mao, P.C.; Tian, X.X. An assessment of Agropyron cristatum tolerance to cadmium contaminated soil. Biol. Plant. 2014, 58, 174–178. [Google Scholar] [CrossRef]
- Asay, K.H. Breeding potentials in perennial Triticeae grasses. Hereditas 2008, 116, 167–173. [Google Scholar] [CrossRef]
- Han, H.; Liu, W.; Zhang, J.; Zhou, S.; Yang, X.; Li, X.; Li, L. Identification of P genome chromosomes in Agropyron cristatum and wheat–A. cristatum derivative lines by FISH. Sci. Rep. 2019, 9, 9712. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Jahier, J.; Cauderon, Y. Production and cytogenetic analysis of BC1, BC2, and BC3 progenies of an intergeneric hybrid between Triticum aestivum (L.) Thell. and tetraploid Agropyron cristatum (L.) Gaertn. Theor. Appl. Genet. 1992, 84, 698–703. [Google Scholar] [CrossRef]
- Limin, A.E.; Flower, D.B. An interspecific hybrid and amphiploid produced from Triticum aestivum crosses with Agropyron cristatum and Agropyron desertorum. Genome 1990, 33, 581–584. [Google Scholar] [CrossRef]
- Soliman, M.H.; Cabrera, A.; Sillero, J.C.; Rubiales, D. Genomic constitution and expression of disease resistance in Agropyron cristatum x durum wheat derivatives. Breed. Sci. 2007, 57, 17–21. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhang, J.; Liu, W.; Han, H.; Lu, Y.; Yang, X.; Li, X.; Li, L. Introgression of Agropyron cristatum 6P chromosome segment into common wheat for enhanced thousand-grain weight and spike length. Theor. Appl. Genet. 2015, 128, 1827–1837. [Google Scholar] [CrossRef]
- Ochoa, V.; Madrid, E.; Said, M.; Rubiales, D.; Cabrera, A. Molecular and cytogenetic characterization of a common wheat–Agropyron cristatum chromosome translocation conferring resistance to leaf rust. Euphytica 2015, 201, 89–95. [Google Scholar] [CrossRef]
- Zhang, Z.; Han, H.; Liu, W.; Song, L.; Zhang, J.; Zhou, S.; Yang, X.; Li, X.; Li, L. Deletion mapping and verification of an enhanced-grain number per spike locus from the 6PL chromosome arm of Agropyron cristatum in common wheat. Theor. Appl. Genet. 2019, 132, 2815–2827. [Google Scholar] [CrossRef]
- Wu, J.; Yang, X.; Wang, H.; Li, H.; Li, L.; Li, X.; Liu, W. The introgression of chromosome 6P specifying for increased numbers of florets and kernels from Agropyron cristatum into wheat. Theor. Appl. Genet. 2006, 114, 13–20. [Google Scholar] [CrossRef]
- Hao, M.; Zhang, L.; Ning, S.; Huang, L.; Yuan, Z.; Wu, B.; Yan, Z.; Dai, S.; Jiang, B.; Zheng, Y.; et al. The resurgence of introgression breeding, as exemplified in wheat improvement. Front. Plant Sci. 2020, 11, 252. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Jahier, J.; Cauderon, Y. Production and cytogenetical studies of hybrids between Triticum aestivum L. Thell and Agropyron cristatum (L.) Gaertn. Comptes. Rendus. l’Acad. Des. Sci. Série 3 Sci. La Vie 1989, 308, 425–430. [Google Scholar]
- Chen, Q.; Lu, Y.L.; Jahier, J.; Bernard, M. Identification of wheat–Agropyron cristatum monosomic addition lines by RFLP analysis using a set of assigned wheat DNA probes. Theor. Appl. Genet. 1994, 89, 70–75. [Google Scholar] [CrossRef]
- Luan, Y.; Wang, X.; Liu, W.; Li, C.; Zhang, J.; Gao, A.; Wang, Y.; Yang, X.; Li, L. Production and identification of wheat–Agropyron cristatum 6P translocation lines. Planta 2010, 232, 501–510. [Google Scholar] [CrossRef] [Green Version]
- Song, L.; Jiang, L.; Han, H.; Gao, A.; Yang, X.; Li, L.; Liu, W. Efficient induction of wheat–Agropyron cristatum 6P translocation lines and GISH detection. PLoS ONE 2013, 8, e69501. [Google Scholar] [CrossRef] [Green Version]
- Han, H.; Bai, L.; Su, J.; Zhang, J.; Song, L.; Gao, A.; Yang, X.; Li, X.; Liu, W.; Li, L. Genetic rearrangements of six wheat–Agropyron cristatum 6P addition lines revealed by molecular markers. PLoS ONE 2014, 9, e91066. [Google Scholar] [CrossRef] [Green Version]
- Copete, A.; Cabrera, A. Chromosomal location of genes for resistance to powdery mildew in Agropyron cristatum and mapping of conserved orthologous set molecular markers. Euphytica 2017, 213, 1–9. [Google Scholar] [CrossRef]
- Rey, E.; Molnár, I.; Doležel, J. Genomics of wild relatives and alien introgressions. In Alien Introgression in Wheat; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 347–381. [Google Scholar]
- Dai, C.; Zhang, J.-P.; Wu, X.-Y.; Yang, X.-M.; Li, X.-Q.; Liu, W.-H.; Gao, A.-N.; Li, L.-H. Development of EST markers specific to Agropyron cristatum chromosome 6P in common wheat background. Acta Agron. Sin. 2013, 38, 1791–1801. [Google Scholar] [CrossRef]
- Lu, M.; Lu, Y.; Li, H.; Pan, C.; Guo, Y.; Zhang, J.; Yang, X.; Li, X.; Liu, W.; Li, L. Transferring desirable genes from Agropyron cristatum 7P chromosome into common wheat. PLoS ONE 2016, 11, e0159577. [Google Scholar] [CrossRef] [Green Version]
- Said, M.; Parada, A.C.; Gaál, E.; Molnár, I.; Cabrera, A.; Doležel, J.; Vrána, J. Uncovering homeologous relationships between tetraploid Agropyron cristatum and bread wheat genomes using COS markers. Theor. Appl. Genet. 2019, 132, 2881–2898. [Google Scholar] [CrossRef] [Green Version]
- Taheri, S.; Abdullah, T.L.; Yusop, M.R.; Hanafi, M.M.; Sahebi, M.; Azizi, P.; Shamshiri, R.R. Mining and development of novel SSR markers using Next Generation Sequencing (NGS) data in plants. Molecules 2018, 23, 399. [Google Scholar] [CrossRef] [Green Version]
- Córdoba, J.M.; Chavarro, C.; Rojas, F.; Muñoz, C.; Blair, M.W. Identification and mapping of simple sequence repeat markers from common bean (Phaseolus vulgaris L.) bacterial artificial chromosome end sequences for genome characterization and genetic-physical map integration. Plant Genome 2010, 3, 154–165. [Google Scholar] [CrossRef]
- Ren, Y.; Zhao, H.; Kou, Q.; Jiang, J.; Guo, S.; Zhang, H.; Hou, W.; Zou, X.; Sun, H.; Gong, G.; et al. A high resolution genetic map anchoring scaffolds of the sequenced watermelon genome. PLoS ONE 2012, 7, e29453. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tabkhkar, N.; Rabiei, B.; Samizadeh Lahiji, H.; Hosseini Chaleshtori, M. Genetic variation and association analysis of the SSR markers linked to the major drought-yield QTLs of rice. Biochem. Genet. 2018, 56, 356–374. [Google Scholar] [CrossRef] [PubMed]
- Shehata, A.I.; Al-Ghethar, H.A.; Al-Homaidan, A.A. Application of simple sequence repeat (SSR) markers for molecular diversity and heterozygosity analysis in maize inbred lines. Saudi J. Biol. Sci. 2009, 16, 57–62. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Komínková, E.; Dreiseitl, A.; Maleèková, E.; Doležel, J.; Valárik, M. Genetic diversity of Blumeria graminis f. sp. hordei in central Europe and its comparison with australian population. PLoS ONE 2016, 11, e0167099. [Google Scholar] [CrossRef] [PubMed]
- Christelová, P.; De Langhe, E.; Hřibová, E.; Čížková, J.; Sardos, J.; Hušáková, M.; Van den houwe, I.; Sutanto, A.; Kepler, A.K.; Swennen, R.; et al. Molecular and cytological characterization of the global Musa germplasm collection provides insights into the treasure of banana diversity. Biodivers. Conserv. 2017, 26, 801–824. [Google Scholar] [CrossRef]
- Nyine, M.; Uwimana, B.; Swennen, R.; Batte, M.; Brown, A.; Christelová, P.; Hribová, E.; Lorenzen, J.; Doleziel, J. Trait variation and genetic diversity in a banana genomic selection training population. PLoS ONE 2017, 12, e0178734. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, X.; Adedze, Y.M.N.; Chofong, G.N.; Gandeka, M.; Deng, Z.; Teng, L.; Zhang, X.; Sun, G.; Si, L.; Li, W. Identification of high-efficiency SSR markers for assessing watermelon genetic purity. J. Genet. 2018, 97, 1295–1306. [Google Scholar] [CrossRef]
- Said, M.; Hřibová, E.; Danilova, T.V.; Karafiátová, M.; Čížková, J.; Friebe, B.; Doležel, J.; Gill, B.S.; Vrána, J. The Agropyron cristatum karyotype, chromosome structure and cross-genome homoeology as revealed by fluorescence in situ hybridization with tandem repeats and wheat single-gene probes. Theor. Appl. Genet. 2018, 131, 2213–2227. [Google Scholar] [CrossRef] [Green Version]
- Doležel, J.; Číhalíková, J.; Lucretti, S. A high-yield procedure for isolation of metaphase chromosomes from root tips of Vicia faba L. Planta 1992, 188, 93–98. [Google Scholar] [CrossRef]
- Mayer, K.F.X.; Waugh, R.; Langridge, P.; Close, T.J.; Wise, R.P.; Graner, A.; Matsumoto, T.; Sato, K.; Schulman, A.; Ariyadasa, R.; et al. A physical, genetic and functional sequence assembly of the barley genome. Nature 2012, 491, 711–716. [Google Scholar] [CrossRef]
- Bartoš, J.; Paux, E.; Kofler, R.; Havránková, M.; Kopecký, D.; Suchánková, P.; Šafář, J.; Šimková, H.; Town, C.D.; Lelley, T.; et al. A first survey of the rye (Secale cereale) genome composition through BAC end sequencing of the short arm of chromosome 1R. BMC Plant Biol. 2008, 8, 95. [Google Scholar] [CrossRef]
- Varshney, R.K.; Song, C.; Saxena, R.K.; Azam, S.; Yu, S.; Sharpe, A.G.; Cannon, S.; Baek, J.; Rosen, B.D.; Tar’an, B.; et al. Draft genome sequence of chickpea (Cicer arietinum) provides a resource for trait improvement. Nat. Biotechnol. 2013, 31, 240–246. [Google Scholar] [CrossRef] [Green Version]
- Kreplak, J.; Madoui, M.A.; Cápal, P.; Novák, P.; Labadie, K.; Aubert, G.; Bayer, P.E.; Gali, K.K.; Syme, R.A.; Main, D.; et al. A reference genome for pea provides insight into legume genome evolution. Nat. Genet. 2019, 51, 1411–1422. [Google Scholar] [CrossRef]
- Appels, R.; Eversole, K.; Feuillet, C.; Keller, B.; Rogers, J.; Stein, N.; Pozniak, C.J.; Choulet, F.; Distelfeld, A.; Poland, J.; et al. Shifting the limits in wheat research and breeding using a fully annotated reference genome. Science 2018, 361, aar7191. [Google Scholar] [CrossRef] [Green Version]
- Lukaszewski, A.J.; Alberti, A.; Sharpe, A.; Kilian, A.; Stanca, A.M.; Keller, B.; Clavijo, B.J.; Friebe, B.; Gill, B.; Wulff, B.; et al. A chromosome-based draft sequence of the hexaploid bread wheat (Triticum aestivum) genome. Science 2014, 345, 1251788. [Google Scholar] [CrossRef]
- Požárková, D.; Koblížková, A.; Román, B.; Torres, A.M.; Lucretti, S.; Lysák, M.; Doležel, J.; Macas, J. Development and characterization of microsatellite markers from chromosome 1-specific DNA libraries of Vicia faba. Biol. Plant. 2002, 45, 337–345. [Google Scholar] [CrossRef]
- Shatalina, M.; Wicker, T.; Buchmann, J.P.; Oberhaensli, S.; Šimková, H.; Doležel, J.; Keller, B. Genotype-specific SNP map based on whole chromosome 3B sequence information from wheat cultivars Arina and Forno. Plant Biotechnol. J. 2013, 11, 23–32. [Google Scholar] [CrossRef] [Green Version]
- Mazaheri, M.; Kianian, P.M.A.; Mergoum, M.; Valentini, G.L.; Seetan, R.; Pirseyedi, S.M.; Kumar, A.; Gu, Y.Q.; Stein, N.; Kubaláková, M.; et al. Transposable element junctions in marker development and genomic characterization of barley. Plant Genome 2014, 7, plantgenome2013.10.0036. [Google Scholar] [CrossRef]
- Cápal, P.; Blavet, N.; Vrána, J.; Kubaláková, M.; Doležel, J. Multiple displacement amplification of the DNA from single flow-sorted plant chromosome. Plant J. 2015, 84, 838–844. [Google Scholar] [CrossRef]
- Šimková, H.; Svensson, J.T.; Condamine, P.; Hřibová, E.; Suchánková, P.; Bhat, P.R.; Bartoš, J.; Šafář, J.; Close, T.J.; Doležel, J. Coupling amplified DNA from flow-sorted chromosomes to high-density SNP mapping in barley. BMC Genom. 2008, 9, 294. [Google Scholar] [CrossRef] [Green Version]
- Campbell, M.S.; Holt, C.; Moore, B.; Yandell, M. Genome annotation and curation using MAKER and MAKER-P. Curr. Protoc. Bioinform. 2014, 2014, 4.11.1–14.11.39. [Google Scholar] [CrossRef] [Green Version]
- Zwyrtková, J.; Němečková, A.; Čížková, J.; Holušová, K.; Kapustová, V.; Svačina, R.; Kopecký, D.; Till, B.J.; Doležel, J.; Hřibová, E. Comparative analyses of DNA repeats and identification of a novel Fesreba centromeric element in fescues and ryegrasses. BMC Plant Biol. 2020, 20, 280. [Google Scholar] [CrossRef]
- Presting, G.G.; Malysheva, L.; Fuchs, J.; Schubert, I. A TY3/GYPSY retrotransposon-like sequence localizes to the centromeric regions of cereal chromosomes. Plant J. 1998, 16, 721–728. [Google Scholar] [CrossRef]
- Hudakova, S.; Michalek, W.; Presting, G.G.; Hoopen, R.T.; Dos Santos, K.; Jasencakova, Z.; Schubert, I. Sequence organization of barley centromeres. Nucleic Acids Res. 2001, 29, 5029–5035. [Google Scholar] [CrossRef]
- Neumann, P.; Navrátilová, A.; Koblížková, A.; Kejnovsk, E.; Hřibová, E.; Hobza, R.; Widmer, A.; Doležel, J.; MacAs, J. Plant centromeric retrotransposons: A structural and cytogenetic perspective. Mob. DNA 2011, 2, 4. [Google Scholar] [CrossRef] [Green Version]
- Zwyrtková, J.; Šimková, H.; Doležel, J. Chromosome genomics uncovers plant genome organization and function. Biotechnol. Adv. 2021, 46, 107659. [Google Scholar] [CrossRef]
- Schreiber, M.; Wright, F.; MacKenzie, K.; Hedley, P.E.; Schwerdt, J.G.; Little, A.; Burton, R.A.; Fincher, G.B.; Marshall, D.; Waugh, R.; et al. The barley genome sequence assembly reveals three additional members of the CslF (1,3;1,4)-β-Glucan Synthase gene family. PLoS ONE 2014, 9, e90888. [Google Scholar] [CrossRef] [Green Version]
- Darko, E.; Khalil, R.; Dobi, Z.; Kovács, V.; Szalai, G.; Janda, T.; Molnár, I. Addition of Aegilops biuncialis chromosomes 2M or 3M improves the salt tolerance of wheat in different way. Sci. Rep. 2020, 10, 22327. [Google Scholar] [CrossRef]
- Zhang, Z.; Song, L.; Han, H.; Zhou, S.; Zhang, J.; Yang, X.; Li, X.; Liu, W.; Li, L. Physical localization of a locus from Agropyron cristatum conferring resistance to stripe rust in common wheat. Int. J. Mol. Sci. 2017, 18, 2403. [Google Scholar] [CrossRef] [Green Version]
- Song, L.; Lu, Y.; Zhang, J.; Pan, C.; Yang, X.; Li, X.; Liu, W.; Li, L. Physical mapping of Agropyron cristatum chromosome 6P using deletion lines in common wheat background. Theor. Appl. Genet. 2016, 129, 1023–1034. [Google Scholar] [CrossRef]
- Matsumoto, T.; Wu, J.; Kanamori, H.; Katayose, Y.; Fujisawa, M.; Namiki, N.; Mizuno, H.; Yamamoto, K.; Antonio, B.A.; Baba, T.; et al. The map-based sequence of the rice genome. Nature 2005, 436, 793–800. [Google Scholar] [CrossRef]
- Schnable, P.S.; Ware, D.; Fulton, R.S.; Stein, J.C.; Wei, F.; Pasternak, S.; Liang, C.; Zhang, J.; Fulton, L.; Graves, T.A.; et al. The B73 maize genome: Complexity, diversity, and dynamics. Science 2009, 326, 1112–1115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wicker, T.; Gundlach, H.; Spannagl, M.; Uauy, C.; Borrill, P.; Ramírez-González, R.H.; De Oliveira, R.; Mayer, K.F.X.; Paux, E.; Choulet, F. Impact of transposable elements on genome structure and evolution in bread wheat. Genome Biol. 2018, 19, 103. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Li, X.; Zhou, X.; Li, M.; Zhang, F.; Schwarzacher, T.; Heslop-Harrison, J.S. The repetitive DNA landscape in Avena (Poaceae): Chromosome and genome evolution defined by major repeat classes in whole-genome sequence reads. BMC Plant Biol. 2019, 19, 226. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Fan, C.; Li, S.; Chen, Y.; Wang, R.R.C.; Zhang, X.; Han, F.; Hu, Z. The diversity of sequence and chromosomal distribution of new transposable element-related segments in the rye genome revealed by FISH and lineage annotation. Front. Plant Sci. 2017, 8, 1706. [Google Scholar] [CrossRef] [Green Version]
- Raskina, O. Transposable elements in the organization and diversification of the genome of Aegilops speltoides Tausch (Poaceae, Triticeae). Int. J. Genom. 2018, 2018, 4373089. [Google Scholar] [CrossRef] [Green Version]
- Sanei, M.; Pickering, R.; Kumke, K.; Nasuda, S.; Houben, A. Loss of centromeric histone H3 (CENH3) from centromeres precedes uniparental chromosome elimination in interspecific barley hybrids. Proc. Natl. Acad. Sci. USA 2011, 108, E498–E505. [Google Scholar] [CrossRef] [Green Version]
- Quraishi, U.M.; Abrouk, M.; Bolot, S.; Pont, C.; Throude, M.; Guilhot, N.; Confolent, C.; Bortolini, F.; Praud, S.; Murigneux, A.; et al. Genomics in cereals: From genome-wide conserved orthologous set (COS) sequences to candidate genes for trait dissection. Funct. Integr. Genom. 2009, 9, 473–484. [Google Scholar] [CrossRef]
- Howard, T.; Rejab, N.A.; Griffiths, S.; Leigh, F.; Leverington-Waite, M.; Simmonds, J.; Uauy, C.; Trafford, K. Identification of a major QTL controlling the content of B-type starch granules in Aegilops. J. Exp. Bot. 2011, 62, 2217–2228. [Google Scholar] [CrossRef] [Green Version]
- Naranjo, T. Variable patterning of chromatin remodeling, telomere positioning, synapsis, and chiasma formation of individual rye chromosomes in meiosis of wheat-rye additions. Front. Plant Sci. 2018, 9, 880. [Google Scholar] [CrossRef]
- Perničková, K.; Koláčková, V.; Lukaszewski, A.J.; Fan, C.; Vrána, J.; Duchoslav, M.; Jenkins, G.; Phillips, D.; Šamajová, O.; Sedlářová, M.; et al. Instability of alien chromosome introgressions in wheat associated with improper positioning in the nucleus. Int. J. Mol. Sci. 2019, 20, 1448. [Google Scholar] [CrossRef] [Green Version]
- Danilova, T.V.; Friebe, B.; Gill, B.S. Development of a wheat single gene FISH map for analyzing homoeologous relationship and chromosomal rearrangements within the Triticeae. Theor. Appl. Genet. 2014, 127, 715–730. [Google Scholar] [CrossRef] [Green Version]
- Luo, M.C.; Deal, K.R.; Akhunov, E.D.; Akhunova, A.R.; Anderson, O.D.; Anderson, J.A.; Blake, N.; Clegg, M.T.; Coleman-Derr, D.; Conley, E.J.; et al. Genome comparisons reveal a dominant mechanism of chromosome number reduction in grasses and accelerated genome evolution in Triticeae. Proc. Natl. Acad. Sci. USA 2009, 106, 15780–15785. [Google Scholar] [CrossRef] [Green Version]
- Mellish, A.; Coulman, B.; Ferdinandez, Y. Genetic relationships among selected crested wheatgrass cultivars and species determined on the basis of AFLP markers. Crop Sci. 2002, 42, 1662–1668. [Google Scholar] [CrossRef]
- Wang, W.W.; Tan, Z.Y.; Xu, Y.Q.; Zhu, A.A.; Li, Y.; Yao, J.; Tian, R.; Fang, X.M.; Liu, X.Y.; Tian, Y.M.; et al. Chromosome structural variation of two cultivated tetraploid cottons and their ancestral diploid species based on a new high-density genetic map. Sci. Rep. 2017, 7, 7640. [Google Scholar] [CrossRef]
- Tang, H.; Lyons, E.; Town, C.D. Optical mapping in plant comparative genomics. Gigascience 2015, 4, 3. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Guan, R.; Liu, X.; Zhang, H.; Song, B.; Xu, Q.; Fan, G.; Chen, W.; Wu, X.; Liu, X.; et al. Chromosome level comparative analysis of Brassica genomes. Plant Mol. Biol. 2019, 99, 237–249. [Google Scholar] [CrossRef]
- Jiao, W.B.; Schneeberger, K. The impact of third generation genomic technologies on plant genome assembly. Curr. Opin. Plant Biol. 2017, 36, 64–70. [Google Scholar] [CrossRef]
- Li, S.; Yang, G.; Yang, S.; Just, J.; Yan, H.; Zhou, N.; Jian, H.; Wang, Q.; Chen, M.; Qiu, X.; et al. The development of a high-density genetic map significantly improves the quality of reference genome assemblies for rose. Sci. Rep. 2019, 9, 5985. [Google Scholar] [CrossRef]
- Wang, X.; Liu, H.; Pang, M.; Fu, B.; Yu, X.; He, S.; Tong, J. Construction of a high-density genetic linkage map and mapping of quantitative trait loci for growth-related traits in silver carp (Hypophthalmichthys molitrix). Sci. Rep. 2019, 9, 17506. [Google Scholar] [CrossRef]
- Amarasinghe, S.L.; Su, S.; Dong, X.; Zappia, L.; Ritchie, M.E.; Gouil, Q. Opportunities and challenges in long-read sequencing data analysis. Genome Biol. 2020, 21, 30. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chawla, H.S.; Lee, H.; Gabur, I.; Tamilselvan-Nattar-Amutha, S.; Obermeier, C.; Schiessl, S.; Song, J.; Liu, K.; Guo, L.; Parkin, I.; et al. Long-read sequencing reveals widespread intragenic structural variants in a recent allopolyploid crop plant. Plant Biotechnol. J. 2020, 19, 240–250. [Google Scholar] [CrossRef] [PubMed]
- Said, M.; Kubaláková, M.; Karafiátová, M.; Molnár, I.; Doležel, J.; Vrána, J. Dissecting the complex genome of crested wheatgrass by chromosome flow sorting. Plant Genome 2019, 12, 180096. [Google Scholar] [CrossRef] [PubMed]
- Bolger, A.M.; Lohse, M.; Usadel, B. Trimmomatic: A flexible trimmer for Illumina sequence data. Bioinformatics 2014, 30, 2114–2120. [Google Scholar] [CrossRef] [Green Version]
- Boisvert, S.; Laviolette, F.; Corbeil, J. Ray: Simultaneous assembly of reads from a mix of high-throughput sequencing technologies. J. Comput. Biol. 2010, 17, 1401–1415. [Google Scholar] [CrossRef]
- Thiel, T.; Michalek, W.; Varshney, R.K.; Graner, A. Exploiting EST databases for the development and characterization of gene-derived SSR-markers in barley (Hordeum vulgare L.). Theor. Appl. Genet. 2003, 106, 411–422. [Google Scholar] [CrossRef]
- Untergasser, A.; Cutcutache, I.; Koressaar, T.; Ye, J.; Faircloth, B.C.; Remm, M.; Rozen, S.G. Primer3—new capabilities and interfaces. Nucleic Acids Res. 2012, 40, e115. [Google Scholar] [CrossRef] [Green Version]
- Wu, T.D.; Watanabe, C.K. GMAP: A genomic mapping and alignment program for mRNA and EST sequences. Bioinformatics 2005, 21, 1859–1875. [Google Scholar] [CrossRef] [Green Version]
- Smit, A.; Hubley, R.; Green, P. RepeatMasker Open-4.0. 2013–2015. 2013. Available online: http://www.repeatmasker.org (accessed on 12 February 2022).
- Stanke, M.; Steinkamp, R.; Waack, S.; Morgenstern, B. AUGUSTUS: A web server for gene finding in eukaryotes. Nucleic Acids Res. 2004, 32, W309–W312. [Google Scholar] [CrossRef] [Green Version]
- Bolser, D.M.; Staines, D.M.; Perry, E.; Kersey, P.J. Ensembl plants: Integrating tools for visualizing, mining, and analyzing plant genomic data. In Methods in Molecular Biology; Humana Press Inc.: Totowa, NJ, USA, 2017; Volume 1533, pp. 1–31. [Google Scholar]
- Mascher, M. Pseudomolecules and Annotation of the Second Version of the Reference Genome Sequence Assembly of Barley cv. Morex [Morex V2]; e!DAL-Plant Genomics & Phenomics Research Data Repository (2019-05-09); IPK Gatersleben: Gatersleben, Germany, 2019. [Google Scholar] [CrossRef]
- Hunter, S.; Apweiler, R.; Attwood, T.K.; Bairoch, A.; Bateman, A.; Binns, D.; Bork, P.; Das, U.; Daugherty, L.; Duquenne, L.; et al. InterPro: The integrative protein signature database. Nucleic Acids Res. 2008, 37, D211–D215. [Google Scholar] [CrossRef] [Green Version]
- Altschul, S.F.; Madden, T.L.; Schäffer, A.A.; Zhang, J.; Zhang, Z.; Miller, W.; Lipman, D.J. Gapped BLAST and PSI-BLAST: A new generation of protein database search programs. Nucleic Acids Res. 1997, 25, 3389–3402. [Google Scholar] [CrossRef] [Green Version]
- Consortium, T.U. UniProt: A worldwide hub of protein knowledge. Nucleic Acids Res. 2018, 47, D506–D515. [Google Scholar] [CrossRef] [Green Version]
- Miele, V.; Penel, S.; Duret, L. Ultra-fast sequence clustering from similarity networks with SiLiX. BMC Bioinform. 2011, 12, 116. [Google Scholar] [CrossRef] [Green Version]
- Novák, P.; Neumann, P.; Macas, J. Graph-based clustering and characterization of repetitive sequences in next-generation sequencing data. BMC Bioinform. 2010, 11, 378. [Google Scholar] [CrossRef] [Green Version]
- Katoh, K.; Toh, H. Recent developments in the MAFFT multiple sequence alignment program. Brief. Bioinf. 2008, 9, 286–298. [Google Scholar] [CrossRef] [Green Version]
- Guindon, S.; Dufayard, J.F.; Lefort, V.; Anisimova, M.; Hordijk, W.; Gascuel, O. New algorithms and methods to estimate maximum-likelihood phylogenies: Assessing the performance of PhyML 3.0. Syst. Biol. 2010, 59, 307–321. [Google Scholar] [CrossRef] [Green Version]
- Gouy, M.; Guindon, S.; Gascuel, O. SeaView version 4: A multiplatform graphical user interface for sequence alignment and phylogenetic tree building. Mol. Biol. Evol. 2010, 27, 221–224. [Google Scholar] [CrossRef] [Green Version]
- Anisimova, M.; Gascuel, O. Approximate likelihood-ratio test for branches: A fast, accurate, and powerful alternative. Syst. Biol. 2006, 55, 539–552. [Google Scholar] [CrossRef]
- Kubaláková, M.; Macas, J.; Doležel, J. Mapping of repeated DNA sequences in plant chromosomes by PRINS and C-PRINS. Theor. Appl. Genet. 1997, 94, 758–763. [Google Scholar] [CrossRef]
- Nagaki, K.; Cheng, Z.; Ouyang, S.; Talbert, P.B.; Kim, M.; Jones, K.M.; Henikoff, S.; Buell, C.R.; Jiang, J. Sequencing of a rice centromere uncovers active genes. Nat. Genet. 2004, 36, 138–145. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chromosome * | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Purity (%) | Length (Mb) ** | RayAssembly (bp) | N50 (bp) | Coverage (%) *** | Number of SSRs | Maker & | Maker && | Genes &&& | |
| 1P | 100 | 870 | 99,700,722 | 5724 | 11.6 | 5949 | 3322 | 3307 | 758 |
| 2P | 90 | 1034 | 342,722,238 | 3774 | 33.2 | 19,604 | 7759 | 7700 | 1093 |
| 3P | 98 | 791 | 443,871,941 | 5973 | 56.1 | 32,624 | 11,045 | 10,976 | 1388 |
| 4P | 100 | 757 | 32,166,648 | 8434 | 4.3 | 1136 | 1472 | 1470 | 749 |
| 5P | 98 | 969 | 463,809,210 | 8175 | 47.9 | 34,401 | 11,769 | 11,694 | 1564 |
| 6P | 81 | 974 | 258,122,996 | 2218 | 26.5 | 30,932 | 6817 | 6756 | 867 |
| 7P | 100 | 958 | 147,241,484 | 4886 | 15.4 | 9624 | 2942 | 2911 | 499 |
| Chromosome Addition Line | Chromosome-Short-Arm Addition Line | Chromosome-Long-Arm Addition Line |
|---|---|---|
| 1P | 1PS + 1BL | No line |
| ocwgm001 | ocwgm001 | |
| ocwgm002 | - | |
| ocwgm003 | - | |
| ocwgm004 | - | |
| ocwgm005 | - | |
| ocwgm006 | - | |
| 2P | 2PS | 2PL |
| ocwgm007 | ocwgm007 | - |
| ocwgm008 | ocwgm008 | - |
| ocwgm009 | ocwgm009 | - |
| ocwgm010 | ocwgm010 | - |
| ocwgm011 | ocwgm011 | - |
| ocwgm012 | ocwgm012 | - |
| ocwgm013 | - | ocwgm013 |
| ocwgm014 | - | ocwgm014 |
| ocwgm015 | - | ocwgm015 |
| ocwgm016 | - | ocwgm016 |
| ocwgm017 | - | ocwgm017 |
| ocwgm018 | - | ocwgm018 |
| ocwgm019 | ocwgm019 | ocwgm019 |
| 3P + 3PS | 3PS | No line |
| ocwgm020 | ocwgm020 | |
| ocwgm021 | ocwgm021 | |
| ocwgm022 | ocwgm022 | |
| ocwgm023 | ocwgm023 | |
| ocwgm024 | ocwgm024 | |
| ocwgm025 | ocwgm025 | |
| ocwgm026 | ocwgm026 | |
| ocwgm027 | ocwgm027 | |
| ocwgm028 | ocwgm028 | |
| ocwgm029 | - | |
| ocwgm030 | - | |
| ocwgm031 | - | |
| ocwgm032 | - | |
| ocwgm033 | - | |
| 4P | 4PS | No line |
| ocwgm034 | ocwgm034 | |
| ocwgm035 | ocwgm035 | |
| ocwgm036 | ocwgm036 | |
| ocwgm037 | ocwgm037 | |
| ocwgm038 | ocwgm038 | |
| ocwgm039 | - | |
| ocwgm040 | - | |
| ocwgm041 | - | |
| ocwgm042 | - | |
| ocwgm043 | - | |
| ocwgm044 | - | |
| 5P | No line | 5PL |
| ocwgm045 | - | |
| ocwgm046 | ocwgm046 | |
| ocwgm047 | ocwgm047 | |
| ocwgm048 | ocwgm048 | |
| 6P | 6PS | 6PL |
| ocwgm049 | ocwgm049 | - |
| ocwgm050 | ocwgm050 | - |
| ocwgm051 | ocwgm051 | - |
| ocwgm052 | ocwgm052 | - |
| ocwgm053 | ocwgm053 | - |
| ocwgm054 | ocwgm054 | - |
| ocwgm055 | ocwgm055 | - |
| ocwgm056 | ocwgm056 | - |
| ocwgm057 | - | ocwgm057 |
| ocwgm058 | - | ocwgm058 |
| - | - | ocwgm059 |
| ocwgm060 | - | - |
| ocwgm061 | - | - |
| ocwgm062 | - | - |
| ocwgm063 | - | - |
| 7P * | No line | No line |
| ocwgm064 | ||
| ocwgm065 | ||
| ocwgm066 | ||
| ocwgm067 | ||
| ocwgm068 | ||
| ocwgm069 | ||
| ocwgm070 | ||
| ocwgm071 | ||
| ocwgm072 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zwyrtková, J.; Blavet, N.; Doležalová, A.; Cápal, P.; Said, M.; Molnár, I.; Vrána, J.; Doležel, J.; Hřibová, E. Draft Sequencing Crested Wheatgrass Chromosomes Identified Evolutionary Structural Changes and Genes and Facilitated the Development of SSR Markers. Int. J. Mol. Sci. 2022, 23, 3191. https://doi.org/10.3390/ijms23063191
Zwyrtková J, Blavet N, Doležalová A, Cápal P, Said M, Molnár I, Vrána J, Doležel J, Hřibová E. Draft Sequencing Crested Wheatgrass Chromosomes Identified Evolutionary Structural Changes and Genes and Facilitated the Development of SSR Markers. International Journal of Molecular Sciences. 2022; 23(6):3191. https://doi.org/10.3390/ijms23063191
Chicago/Turabian StyleZwyrtková, Jana, Nicolas Blavet, Alžběta Doležalová, Petr Cápal, Mahmoud Said, István Molnár, Jan Vrána, Jaroslav Doležel, and Eva Hřibová. 2022. "Draft Sequencing Crested Wheatgrass Chromosomes Identified Evolutionary Structural Changes and Genes and Facilitated the Development of SSR Markers" International Journal of Molecular Sciences 23, no. 6: 3191. https://doi.org/10.3390/ijms23063191